近期我们发现监控图像会不定期的出现断点情况,图像上一根连续的曲线突然就断开了,如下
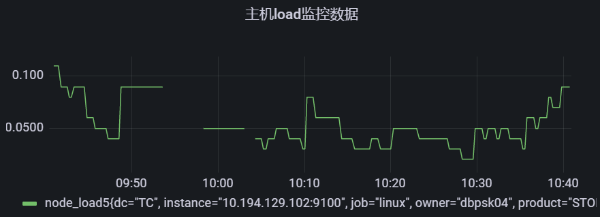
经过排查发现,数据是通过Prometheus的联邦模式从别的Prometheus实例采集上来的,于是我们去原实例上进行查询,发现原始数据没有断点,如下图,
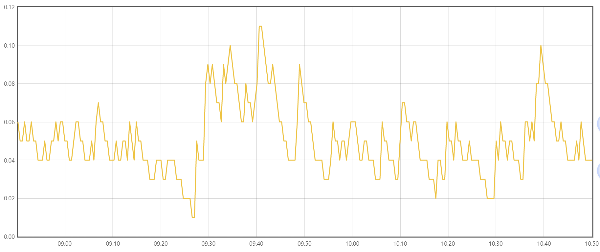
那么问题可能处在Prometheus联邦采集上,经过查找,Prometheus联邦本身有以下几个参数也存在一些可疑
up{ job=~"._federate"}
scrape_samples_scraped{ job=~"._federate"}
scrape_duration_seconds{ job=~".*_federate"}

果然,我们在联邦的监控数据上发现,一些超时的情况(默认30s超时),超时以后会有一些时间点没有采集到数据(黄色图中数据采集量是零)
我们原先设定的参数是
scrape_interval: 45s
scrape_timeout: 30s
我们修改了一下
scrape_interval: 60s
scrape_timeout: 45s注意这里,scrape_interval要大于scrape_timeout,否则会报错。
scrape timeout greater than scrape interval for scrape config with job name
经过了几天的运行,再也没有发现断图的情况了。
由此我们可以推断,Prometheus每隔scrape_interval去采集一次数据,自发起采集请求开始,一直到scrape_timeout结束的时间内,如果数据顺利采集完毕,那就没问题录入,如果这个时间不能采集完毕,就会出现丢数据,甚至整个采集的数据都丢失的情况。
大家在使用Prometheus的过程中,应该注意一下这个点。
相应的我们添加了两个报警规则,用来监控联邦掉线和收集不到数据的情况
- alert: prometheus federate offline
expr: up{job=~".*_federate"} < 1
for: 10m
labels:
severity: Warning
team: prometheus
annotations:
summary: '联邦掉线'
- alert: prometheus federate no data
expr: scrape_samples_scraped{ job=~".*_federate"} == 0
for: 15m
labels:
severity: Warning
team: prometheus
annotations:
summary: '联邦采集不到数据'转载请注明:IPCPU-网络之路 » Prometheus联邦采集超时导致监控图像出现断点