Python处理Excel.md
Excel预处理
Python处理Excel文件的库有很多很多,但是Excel的格式也有很多,xls、xlsx、xlsm,真是看花眼,有人列举了一些常用的库特点
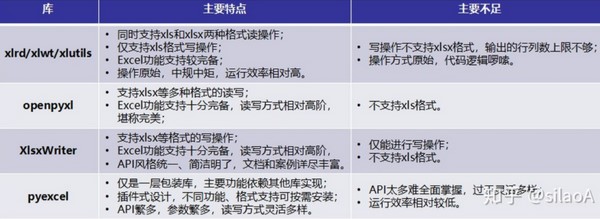
很显然,好多库其中缺点一项就是对于xls没有支持,那咋办?
一般来说我们建议在Excel文件放入Python处理之前,先进行格式转换,统一转换为xlsx格式,然后在使用python调用处理。
import win32com.client as win32
fname = "full+path+to+xls_file"
excel = win32.gencache.EnsureDispatch('Excel.Application')
wb = excel.Workbooks.Open(fname)
wb.SaveAs(fname+"x", FileFormat = 51)
wb.Close()
excel.Application.Quit()
# FileFormat = 51 is for .xlsx extension
# FileFormat = 56 is for .xls extension
# 几点注意事项:
# 1. 系统需要安装Excel或者WPS并且有默认excel程序关联,WPS设置成默认程序也可以
# 2. 文件路径必须写完整路径,因为Excel程序无法识别Python文件的目录
# 3. win32com库,使用pip install pypiwin32安装openpyxl库的使用
openpyxl是一个功能强大的Excel处理库,是一个比较综合的工具,能够同时读取和修改Excel文档。
from openpyxl import load_workbook
from openpyxl.styles import colors, Font, Fill, NamedStyle
#基础概念:一个Excel文件就是一个workbook,里面有多个worksheet
#每个sheet中有若干个单元格cell
# 加载文件, 如果文件有公式需要加上data_only
wb = load_workbook('./5a.xlsx', data_only=True)
# 读取sheetname
print('==输出文件所有工作表名:\n', wb.sheetnames)
#添加删除sheet
# 创建的sheet必须要赋值给一个对象,不然只有名字但是没有实际的新表
ws4 = wb.create_sheet(index=0, title='newsheet')
# 什么参数都不写的话,默认插入到最后一个位置且名字为sheet,sheet1...按照顺序排列
ws5 = wb.create_sheet()
# 删除sheet
wb.remove(ws4) # 这里只能写worksheet对象,不能写sheetname
# 读取sheet1中的有效区域
ws1 = wb['Sheet1']
print('==最大列数为:', ws1.max_column)
print('==最大行数为:', ws1.max_row)
#读取A1单元格的值
print('==读取B2单元格内容')
print(ws1['B2'].coordinate, ws1['B2'].value)
#给A1单元格设置字体格式
ft = Font(name='微软雅黑', color='000000', size=15, b=True)
title = ws1['A1']
title.font = ft
#读取B4:C5
data = ws1['B4:C5']
print(data, type(data))
#遍历sheet1
for row in ws1.iter_rows():
for cell in row:
print(cell.coordinate, cell.value)
#保存修改
wb.save('./5a.xlsx')执行结果
==输出文件所有工作表名:
['Sheet1', 'Sheet2', 'Sheet3']
==最大列数为: 4
==最大行数为: 4
==读取B2单元格内容
B2 66756
((<Cell 'Sheet1'.B4>, <Cell 'Sheet1'.C4>), (<Cell 'Sheet1'.B5>, <Cell 'Sheet1'.C5>)) <class 'tuple'>
pandas库的使用
pandas是我们日常经常用到的数据分析库,我们以前也说过他的DataFrame数据结构类似于Excel表的存储方式,因此pandas处理Excel文件缺失很方便
import pandas as pd
print('==打印sheet内容')
df = pd.read_excel('./5a.xlsx', sheet_name=0) # 读取第1个sheet
print(df)
print('==打印所有sheet名字列表')
workbook = pd.ExcelFile('./5a.xlsx')
print(workbook)
print(workbook.sheet_names)
print('==输出行号', df.index.values)
print('==输出列标题', df.columns.values)
print('==读取某一行数据\n', df.iloc[0].values)
#这里读取数据并不包含表头
print('==读取多行数据\n', df.iloc[[0, 1]].values)
#嵌套列表
print('==读取某一列数据\n', df['总和'].values)
print('==读取某单元格数据\n', df.iloc[1, 3])
#这里不需要嵌套列表,也没有values
#把每一行都转换成字典
test_data=[]
keys = df.columns.values
for i in df.index.values:#获取行号的索引,并对其进行遍历:
# 根据i来获取每一行指定的数据 并利用to_dict转成字典,# loc为按列名索引 iloc 为按位置索引,使用的是 [[行号], [列名]]
row_data = df.loc[i, keys].to_dict()
# 将每一行转换成字典后添加到列表
test_data.append(row_data)
print('==最终获取到的数据是:\n{0}'.format(test_data))
print('==写到新的Excel中')
pd.DataFrame(df).to_excel('new_excel.xlsx', sheet_name='guess', index=False, header=True)输出结果如下
==打印sheet内容
月份 阿里云 cdn 总和
0 7 66756 14021 80777
1 8 65345 16532 81877
2 9 65872 17872 83744
==打印所有sheet名字列表
<pandas.io.excel._base.ExcelFile object at 0x0000023CD8D614F0>
['Sheet1', 'Sheet2', 'Sheet3']
==输出行号 [0 1 2]
==输出列标题 ['月份' '阿里云' 'cdn' '总和']
==读取某一行数据
[ 7 66756 14021 80777]
==读取多行数据
[[ 7 66756 14021 80777]
[ 8 65345 16532 81877]]
==读取某一列数据
[80777 81877 83744]
==读取某单元格数据
81877
==最终获取到的数据是:
[{'月份': 7, '阿里云': 66756, 'cdn': 14021, '总和': 80777}, {'月份': 8, '阿里云': 65345, 'cdn': 16532, '总和': 81877}, {'月份': 9, '阿里云': 65872, 'cdn': 17872, '总和': 83744}]
==写到新的Excel中注意事项:在使用pandas的 df.to_excel(file_path)想要对一个有多张sheet的workbook操作时一定会尴尬的发现:永远只存在最后一次写进去的sheet,其他的都被清空了。这时候需要使用ExcelWriter,如下
import pandas as pd
import numpy as np
writer = pd.ExcelWriter('demo.xlsx') #默认是覆盖模式,会把文件清空再写数据
#writer = pd.ExcelWriter('demo.xlsx', mode='a') #追加模式,文件必须先存在
'''创建数据框1'''
df1 = pd.DataFrame({'V1': np.random.rand(10),
'V2': np.random.rand(10),
'V3': np.random.rand(10)})
df1.to_excel(writer, sheet_name='sheet1', index=False)
'''创建数据框2'''
df2 = pd.DataFrame({'V1': np.random.rand(10),
'V2': np.random.rand(10),
'V3': np.random.rand(10)})
df2.to_excel(writer, sheet_name='sheet2', index=False)
'''数据写出到excel文件中'''
writer.save()参考资料
https://www.jianshu.com/p/720c6653d9b7
转载请注明:IPCPU-网络之路 » Python处理Excel