本文撰写时间是2020年11月,因为技术的发展太快,所以在阅读之前需要留意一下。
一、OCR概述
OCR(optical character recognition)光学字符识别,即对文本资料进行扫描,然后对图像文件进行分析处理,获取文字及版面信息的过程。
这并不是一项新技术,在电脑刚刚普及的2000年初,就有方正OCR、尚书6号等大量光盘盗版软件存在(当时互联网还未普及,盗版软件分发主要靠光盘,一般买一张光盘比如WPS,里面会赠送N多的其他盗版软件)

二、OCR的难点
识别率:不仅要识别印刷的书本、现在更多的需求是识别照片中的文字,这些文字可能是印刷体也可能是手写体,甚至因为拍摄角度原因存在拉伸、模糊等各种变形的情况。

识别速度:在当今的时代,1秒到几秒左右的识别时间已经是用户能够忍受的极限了,若是识别速度慢再加上识别率低,基本上用户要说拜拜了。
三、OCR的发展
在之前,OCR领域主要以传统的识别算法为主,其标准流程包含文本检测、单字符分割、单字符识别、后处理等步骤。其处理的内容主要以印刷体文字为主。

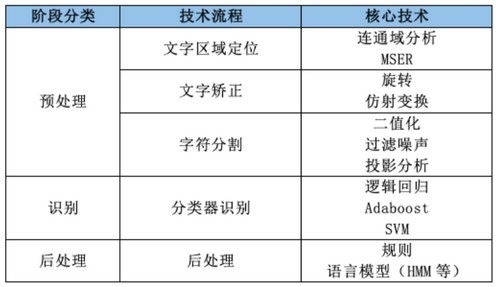
大概是在2012、2013年,深度学习方法开始在图像视频领域大幅超越传统算法,并开始扩展到OCR领域,在此阶段,使用各种算法和大量的图片训练出自己独有的模型,才是技术的核心竞争力。
目前大多数厂商比如百度OCR,提供的都是在线API接口调用的方式来进行识别,这里需要注意的是由于识别速度的要求,上传图片是调用已经训练好的模型库来识别的,不是直接用各种AI算法跑一遍,当然这些图片在识别完以后也会被拿到百度后台进行训练,也就是说用的人越多,训练的图片就越多,模型库识别效果越好。
四、OCR实战
我们这里不谈文字识别的AI训练算法,我也不懂,我们只说实际过程中如何使用。
4.1 利用在线API接口识别
百度腾讯等接口都有免费额度可以使用,一般使用场景足够了,只需要去百度注册账号后获取一组APP ID信息,然后结合官方提供的SDK就可以使用了。
若是对于编程不熟的也可以使用网友封装好的软件
https://github.com/AnyListen/tianruoocr
我们来简单试一下,手写文本如下

识别后的文字如下
每个人的生命中,都该有一次,
为了某个人而忘了自己,不求有结
不求同行,不求留传拥有,基至求
包知流,只求在最轰的年鲜里,选见他。软件必须联网,经抓包分析,走的是搜狗API接口,看源代码中写了搜狗、百度、腾讯,应该是免费额度不足需要轮询使用多家。
类似的还有 https://github.com/AnyListen/tools-ocr
由于这些都是开源的,可以手动修改API接口厂商和里面的APP ID。
4.2 利用开源工具和模型库识别
上面的工具都需要联网,并且还需要免费额度,并且图片传递到互联网上很不安全,所以我们也有不需要联网的离线产品。
百度开源了飞桨PaddleOCR,在发布文档中对比了开源软件的对比情况
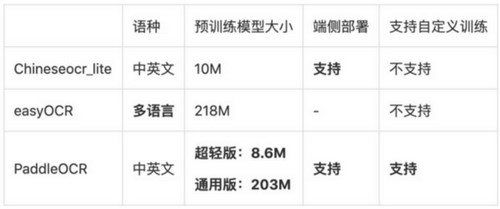
PaddleOCR除了本身包含了已经训练好的模型库以外,还支持自行部署服务器端,这个功能可以说是给企业用户大大的便利。
PaddleOCR本身不是一个可以直接打开的软件,有网友封装了exe软件,软件地址
https://gitee.com/lazytech_group/scr2txt
我们看下识别效果
每一个人的生命中,都左该有一次,
为了某个人师忘了自乙,不求有病子。
不求同行,不求曾给拥有,甚至不求
他知道,只求在最美的年华里,温见他大家看到了吧,对于印刷体来说,一般识别率都很高,手写体识别效果就一般了。
参考资料
https://cloud.tencent.com/developer/article/1588018
https://tech.meituan.com/2018/06/29/deep-learning-ocr.html
https://my.oschina.net/u/4067628/blog/4503775
转载请注明:IPCPU-网络之路 » 谈一谈OCR文字识别