NUMA简介
NUMA(Non-Uniform Memory Access)是起源于AMD Opteron的微架构,同时被Intel Nehalem采用(英特尔志强E5500以上的CPU和桌面的i3、i5、i7均基于此架构)。这也应该是继AMD64后AMD对CPU架构的又一项重要改进。
为什么要有NUMA
在NUMA架构出现前,CPU欢快的朝着频率越来越高的方向发展。受到物理极限的挑战,又转为核数越来越多的方向发展。如果每个core的工作性质都是share-nothing(类似于map-reduce的node节点的作业属性),那么也许就不会有NUMA。由于所有CPU Core都是通过共享一个北桥来读取内存,随着核数如何的发展,北桥在响应时间上的性能瓶颈越来越明显。于是,聪明的硬件设计师们,先到了把内存控制器(原本北桥中读取内存的部分)也做个拆分,平分到了每个core上。于是NUMA就出现了!
NUMA是什么
NUMA架构将整台服务器分为若干个节点,每个节点上有单独的CPU和内存。只有当CPU访问自身节点内存对应的物理地址时,才会有较短的响应时间(后称Local Access)。而如果需要访问其他节点的内存的数据时,就需要通过inter-connect通道访问,响应时间就相比之前变慢了(后称Remote Access)。所以NUMA(Non-Uniform Memory Access)就此得名。如下图。
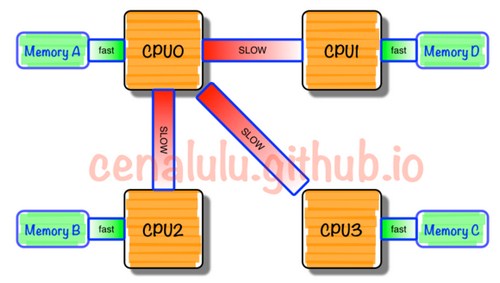
NUMA的缺陷
NUMA的内存分配策略对于进程(或线程)之间来说,并不是公平的。
在现有的Redhat Linux中,localalloc是默认的NUMA内存分配策略,即从当前node上请求分配内存,这个配置选项导致资源独占程序很容易将某个node的内存用尽。而当某个node的内存耗尽时,Linux又刚好将这个node分配给了某个需要消耗大量内存的进程(或线程),swap就妥妥地产生了。尽管此时还有很多page cache可以释放,甚至还有很多的free内存。
在BIOS里关闭NUMA
在BIOS里找到Node Interleaving(一般在Memory setting)
当设置为Disabled:表示启用NUMA,非一致访问方式访问,这是默认配置。
当设置为Enabled:表示smp方式启用内存交错模式,smp的方式,关闭NUMA。
在OS系统层面关闭NUMA
启动MySQL之前使用numactl –interleave=all来修改NUMA策略即可。
硬件层面和软件层面关闭NUMA差距
在os层numa关闭时,打开bios层的numa会影响性能,QPS会下降15-30%;
在bios层面numa关闭时,无论os层面的numa是否打开,都不会影响性能。
监测NUMA
- 判断BIOS层面是否开启NUMA
#@启用NUMA后的显示[root@s101.ipcpu.com ~]# grep -i numa /var/log/dmesgNUMA: Using 31 for the hash shift.pci_bus 0000:00: on NUMA node 0pci_bus 0000:80: on NUMA node 1#@关闭NUMA后的显示# grep -i numa /var/log/dmesgNo NUMA configuration foundpci_bus 0000:00: on NUMA node 0pci_bus 0000:80: on NUMA node 0
- 列举系统上的NUMA节点
[root@s101.ipcpu.com ~]# numactl --hardwareavailable: 2 nodes (0-1)node 0 cpus: 0 1 2 3 4 5 6 7 16 17 18 19 20 21 22 23node 0 size: 16259 MBnode 0 free: 2781 MBnode 1 cpus: 8 9 10 11 12 13 14 15 24 25 26 27 28 29 30 31node 1 size: 16384 MBnode 1 free: 956 MBnode distances:node 0 10: 10 211: 21 10[root@s101.ipcpu.com ~]# lscpuArchitecture: x86_64CPU op-mode(s): 32-bit, 64-bitByte Order: Little EndianCPU(s): 32On-line CPU(s) list: 0-31Thread(s) per core: 2Core(s) per socket: 8Socket(s): 2NUMA node(s): 2Vendor ID: GenuineIntelCPU family: 6Model: 63Stepping: 2CPU MHz: 1200.000BogoMIPS: 5193.47Virtualization: VT-xL1d cache: 32KL1i cache: 32KL2 cache: 256KL3 cache: 20480KNUMA node0 CPU(s): 0-7,16-23NUMA node1 CPU(s): 8-15,24-31
- 显示内存统计数据
[root@s101.ipcpu.com ~]# numastatnode0 node1numa_hit 88443251412 83630576163numa_miss 1479866167 6290100571numa_foreign 6290100571 1479866167interleave_hit 14773 14774local_node 88443238320 83630554722other_node 1479879259 6290122012
当发现numa_miss数值比较高时,说明需要对分配策略进行调整。例如将指定进程关联绑定到指定的CPU上,从而提高内存命中率。
是否需要关闭NUMA
根据具体业务决定NUMA的使用。
如果你的程序是会占用大规模内存的,你大多应该选择关闭NUMA Node的限制(或从硬件关闭NUMA)。因为这个时候你的程序很有几率会碰到NUMA陷阱。
如果你的程序并不占用大内存,而是要求更快的程序运行时间。你大多应该选择限制只访问本NUMA Node的方法来进行处理。
参考资料
http://cenalulu.github.io/linux/numa/
http://mysql.taobao.org/monthly/2015/07/06/
https://www.sqlskills.com/blogs/jonathan/understanding-non-uniform-memory-accessarchitectures-numa/
http://www.cnblogs.com/wjoyxt/p/4804081.html
http://www.stratoscale.com/blog/openstack/cpu-pinning-and-numa-awareness/
http://www.cnblogs.com/yubo/archive/2010/04/23/1718810.html
转载请注明:IPCPU-网络之路 » NUMA概述